Download PerformanceDemo source codeDownload Database script
Introduction
How to find and resolve performance problem of ASP.NET based enterprise application has been discussed so many times. In here, I want to talk about this topic from a different perspective.
Possible Causes of Performance Problem
Performance problem could have many different reasons, such as inferior hardware, poorly designed software, slow network connection, lacking of table index, etc. In here, I will only focus on Database and Application that have most dynamic factors and can be improved or adjusted by software developers.
Database
An enterprise application usually uses relational database as backend to store business data. Due to most enterprise applications don’t deal with massive data and don’t serve client in very complicated environment, so we don’t need to talk about advanced performance topics here, such as data distribution, data partition, high concurrency, etc. A performance problem comes from database can be usually associated with Table design, Index, and Query.
Table design
In most situations, table should be designed to reach 3rd or 4rd normalization form. However, a higher normalization could result in complicated table join in query, so you need to trade off a little bit normalization to gain performance in certain area. Another thing on table design is the field type, such as you should use smallint instead of int when int is not necessary. By giving proper field type, you will have better data type check and smaller data footprint. One more thing about table design is the primary key and foreign key. With appropriate primary key and foreign key assigned will not only guarantees data relationship and data integrity, but also helps query engine to choose the right execution plan.
Index
Index is defined on table, but because it’s very crucial to database performance, so I want to talk about it separately from table design. There are many types of index. Two most frequently used types of index are cluster index and non-cluster index. Cluster index will force database to store data according to the cluster index field(s). If there is no cluster index defined, table data will be stored in heap structure. To retrieve a particular record, a table scan will be conducted. After a cluster index defined (one and only one cluster index can be defined on a table), data are stored in B-tree structure. Data retrieving operation becomes much efficient by using binary search algorithm. Usually, the cluster index is defined on primary key because primary key field is unique and most likely is in integer type. It’s more efficient to be used to organize data in B-tree. Only have cluster index is not enough, we need to add many non-cluster indexes to handle variant situations. The suitable indexes can be added manually from experience or be generated automatically from query optimizer, such as SQL Server Query Optimizer. Have proper indexes defined is not done yet, because database query engine looks at statistics to decide which index should be used if there are more than one index available. So, keep database statistics up-to-date is also very important.
Query
After you have decent table design and proper index specified. The next key factor relates to database performance is query itself. SQL (Structure Query Language) is the standard language used in every database platform. However, a proper written SQL could result in big performance difference compare with improper written SQL. Basic SQL syntax is always the primary choice instead of advanced SQL syntax, e.g. sub query is preferred over user defined function for selecting data. Whether use inner join, outer join, or fields and their sequence in where clauses are all have impact on the performance.
Application
How good the design of an application is also determines how good the system performance is. Especially for algorithms deal with data directly, if application processes data in most efficient way, then the system performance will be better. Vice versa, if the application doesn’t process data so efficiently, then the system will be lagging.
Performance Troubleshooting
How to determine there is a performance problem
For a web application, you can have very scientific approach to gather application performance metrics with tools to show the application is having performance problem, or by rule of thumb, when a web page takes more than 5 seconds to load, then there is a potential performance problem.
Profiling a web page loading time
There are many tools that can be used to measure how long a web page is loaded. Fiddler, Internet Explorer Developer Toolbar, and Firebug are three commonly used tools.
Fiddler
Fiddler is a Web Debugging Proxy which logs all HTTP(S) traffic between client and web server. It is free and can be downloaded from www.fiddler2.com.
Internet Explorer Developer Toolbar
The original Internet Explorer Developer Toolbar is a separate installation that must be downloaded and installed individually. After Internet Explorer 8.0, it becomes a part of default components. Initially Internet Explorer Developer Toolbar doesn’t support network traffic profiling and it is added in later version.
Firebug
Firebug is a web development tool that facilitates the debugging, editing, and monitoring of website’s CSS, HTML, DOM, XHR, and JavaScript. It is an optional add-on of Firefox browser. It needs to be installed explicitly.
How to find the cause of performance problem
After a web performance problem is determined, the next step is to pinpoint where the performance is from.
Profiling Database Activities
The practice I use is to profile database performance first to determine whether the performance problem comes from database. For SQL Server database, we can use SQL Server Profiler to capture all database activities to a particular database and to see which activity looks suspicious. SQL Server Profiler is a part of SQL Server Database Tool.
Analyzing SQL statement
If there is a suspicious activity found that runs for too long, then we can copy the query of that activity out and put it into SQL Server Management Studio to do further analysis.
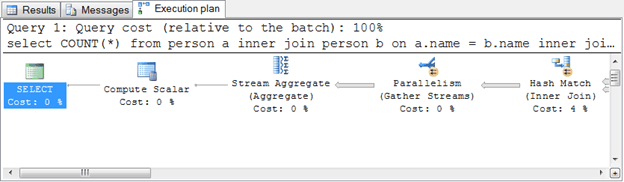
The best way to show how the query gets executed is by looking at the Actual Execution Plan of that query when it is running in SQL Server Management Studio.
If no suspicious long running activity found in SQL Server Profiler, then, the performance problem is most likely from application.
Capturing Memory Dump
To determine which part of the application runs for that long, we can usually use memory dump tool, DebugDiag, to capture several memory dumps at the moment we feel application was stuck.

Analyzing Memory Dump
After done with memory dumping, the dumped memory files can be loaded back into DebugDiag and be used to generate memory dump report. From the memory dump report, we can easily see which function was be executed, therefore, we can go back to the source code to find that function and analyze why it runs for that long, or have unit test for that piece of code with similar environment provided to see whether we can reproduce the long running situation in development environment.
Found No Problem in both Database and Application
If there is no problem found in both database and application, unfortunately, the cause of performance problem is out of software developer’s knowledge domain, therefore we need to ask help from system administrator or network engineer for further troubleshooting.
Experiment
Let’s have two experiments to see how we troubleshoot performance problem in action. One performance problem is from database and another performance problem is from application.
Demo Application
The demo application is created with ASP.NET MVC 4. It has two demo pages: Slow Page and Slow Database Page. The Slow Page has performance problem on application side and Slow Database Page has performance problem on database side.
 Note
Note: the demo application contains impractical code logic and SQL statement that are only for demonstration purpose.
Troubleshooting Database Performance Problem
The Slow Database Page has performance problem. This can be verified with Fiddler.
1. Run Fiddler.
The Fiddler default starts in running state. It will try to capture all HTTP(S) traffics.
2. Click on Slow Database Page link to open it up.
3. You should see an item that has URL to /Home/SlowDatabasePage in Fiddler Web Session panel. (Note: you can stop fiddler capturing to prevent from capturing other HTTP(S) activities)
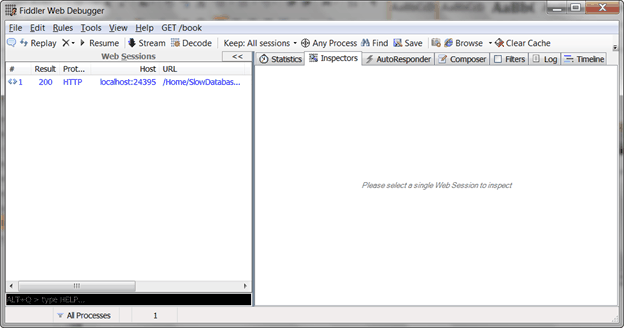
4. By selecting the captured web session item, you can see the total time took to render this page (It is highlight in red box).

This page took more than 15 seconds to load. From this, we can conclude there is a performance issue in Slow Database Page.
After we determined there is a performance problem, the next step is to use SQL Server profiler to profile database activities.
1. Open up SQL Server Profiler.
2. Start a new trace to monitor any database activity happens on PerformanceDemo database. (Note: PerformanceDemo database is the database that our demo application is using at backend.)

3. Reload the Slow Database Page.
4. There are some database activities captured in SQL Server Profiler.
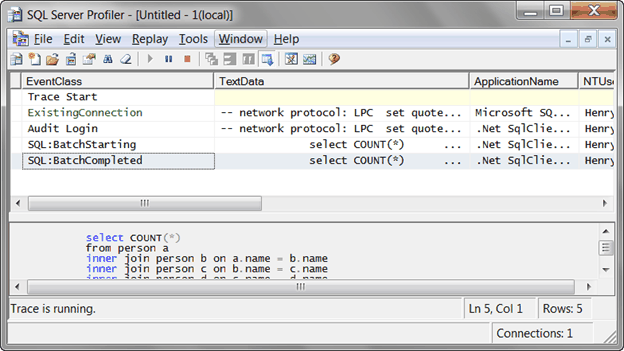
Stop the profiler to prevent from any further database activities be captured.
5. Look through each record in profiler and find the one that has the biggest number of Duration.

There is a query takes 10906 milliseconds, 10.906 seconds, to finish. This tells us that Query has performance problem.
6. By highlighting the record, you can see the full SQL statement in the bottom panel. Select and copy the SQL statement from SQL Server Profiler into SQL Server Management Studio for further analyzing. (Note: the SQL is ridiculously miswritten for demonstration purpose)
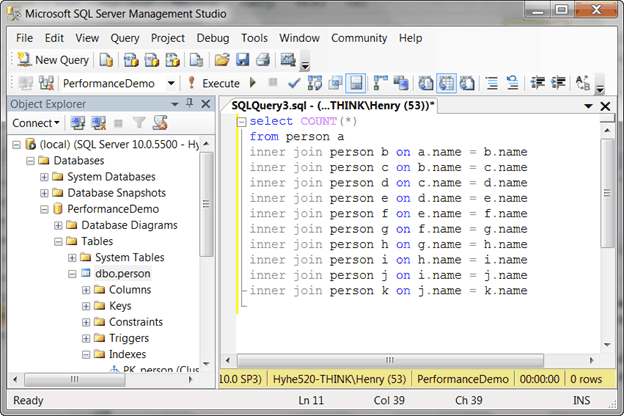
7. Turn on Actual Execution Plan by going to Query -> Include Actual Execution Plan and execute the SQL again.

An Execution Plan tab is shown up in the bottom panel. After selected the Execution plan tab, you can see how SQL Server Query Engine executes this query.

If you study on the execution plan, you can see the query is doing table scan and other inefficient operation.
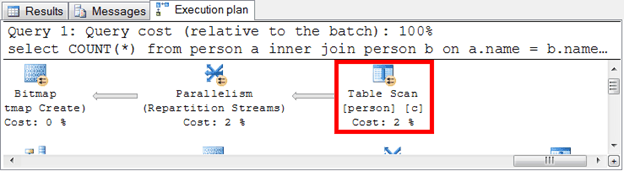
According to what we found in execution plan, we can optimize the query by adding cluster index on Person table to avoid table scan.
Troubleshoot Application Performance Problem
After walked through the steps of troubleshooting database performance problem, let’s take a look how to troubleshoot application performance problem. We can still use above demo application. The Slow Page also has performance problem, this can be confirmed by Fiddler.
1. Run Fiddler.

2. Click on Slow Page link to open it up.

3. You should see an item that has URL to /Home/SlowPage in Fiddler Web Session panel.
4. By selecting the captured web session item, you can see the time took to render the page.
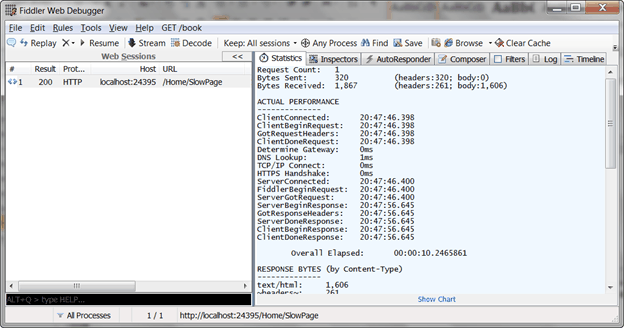
The page took more than 10 seconds to load. OK, from this, we can conclude there is a performance issue in this page.
After we determined there is a performance problem on the page, the next step is to use SQL Server profiler to profile database activities.
1. Open SQL Server Profiler.
2. Start a new trace to monitor any database activity happens on PerformanceDemo database.

3. Reload the Slow Page.
4. Go back to look at the SQL Server Profiler. Nothing is there.
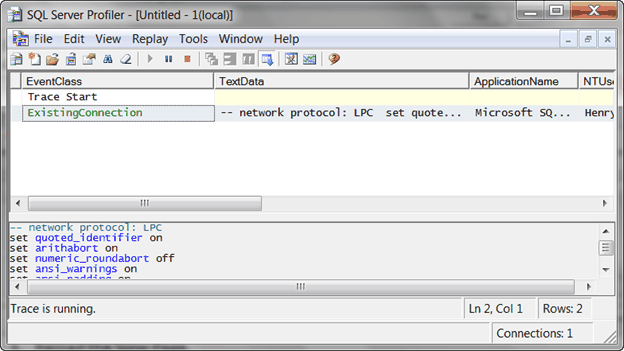
Since nothing is found in SQL Server Profiler, we can infer the performance problem is not from database side.
After database is excluded from the source of performance problem, the only possible source of performance problem we can think is application. However, the question is how to find out which line of code has performance problem. In a real life enterprise web application, a single web page could be designed to accomplish complicated business logic behind the scene. Read through all the source code is not feasible way to tell where and when is the performance problem from. So, what we really need is the runtime state of the application. DebugDiag is the tool we goanna to use to capture the runtime state of the application. You can also use WinDBG if you are more familiar with it. To me, DebugDiag is handier and simpler than WinDBG and it can just fulfill our need. However, in more advanced situation, WinDBG allows sophisticated programmer to step through source code and evaluate every single variable at runtime. Let’s start use DebugDiag to capture the runtime state of our demo application.
1. Open up DebugDiag.
2. Add a rule for a specific process. Though DebugDiag provides a dedicated rule type to monitor long running HTTP request in IIS.
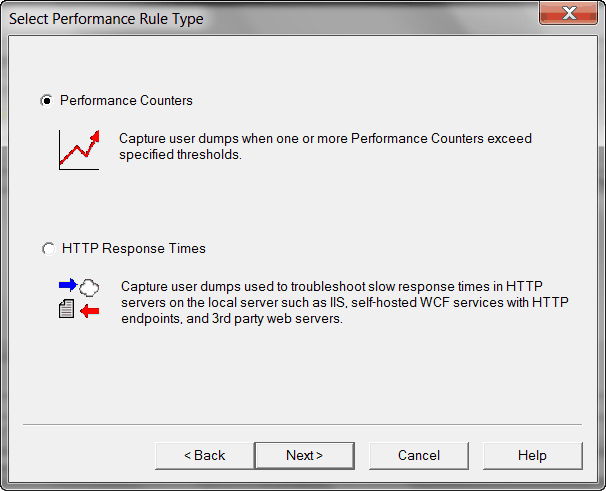
But because our application is running in Visual Studio development web server instead of IIS, so we are not going to choose that one. What we chose is to directly monitor a running process with Crash rule type.
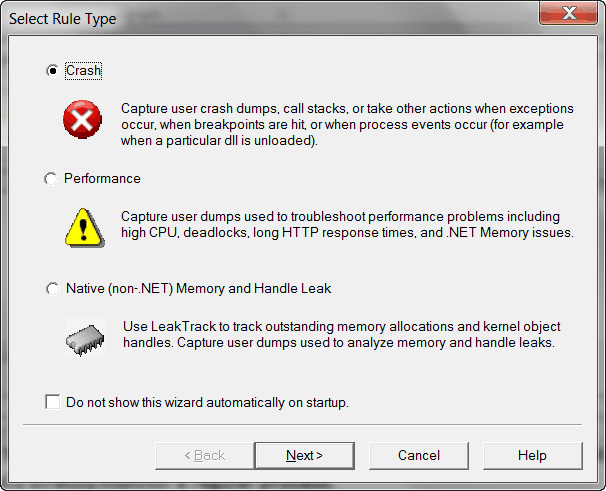
And then select target type, A specific process.

And then select the specific process, WebDev.WebServer40.EXE.
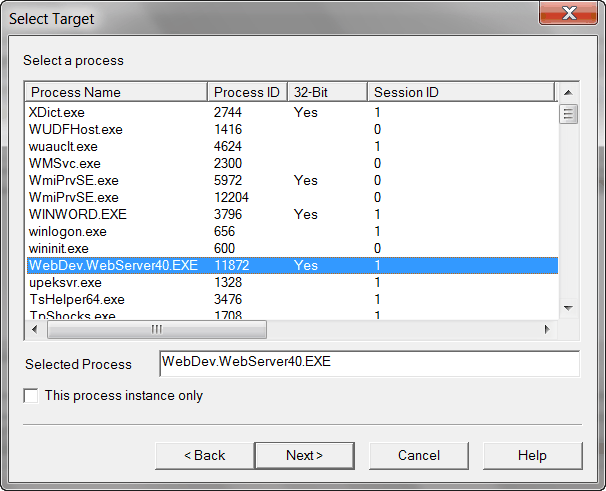
At the end, follow rest of wizard to complete the new rule with all default settings.

3. Reload the Slow Page.
4. Before the page gets complete loaded, quickly switch back to DebugDiag to manually dump a full memory dump.
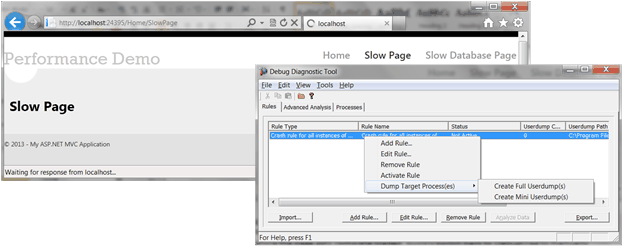
5. After the memory dumping is completed. Switch to Advanced Analysis tab of DebugDiag to load the memory dump and start analysis, and generate the memory dump report.
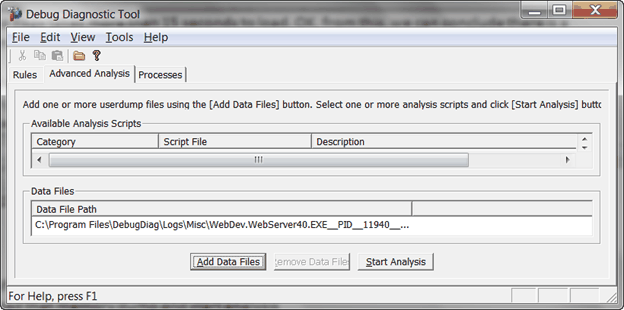
The report is in HTML format

By looking at the report, we can see Thread 15 is the one running in SlowPage action method and there is a Sleep method call inside of it.
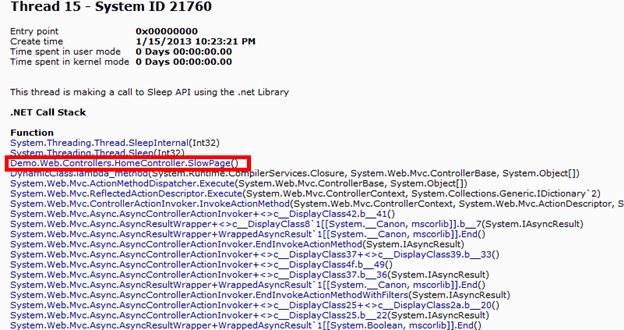
This piece of code is for demonstration purpose, so it doesn’t make any sense. In a real life scenario, we should base on the information we collected from call stack to trace back to original source code. It will most likely give us more clues on why application is running in that area.
Summary
Performance problem in ASP.NET based enterprise web application is a very common problem that most developers have faced before and will probably face in the future. Most performance problems are caused by improper design or coding in application or database. Following the process I introduced above you will be able to have a greater chance reveal the source of performance problem quickly. Let me repeat this process briefly in here.
1. Determine or confirm the performance problem with web debugging tool.
2. Profile database activities.
3. If a suspicious database activity is found, continue on to the next step, otherwise, go to step 6.
4. Copy the suspicious SQL into SQL designing tool for analysis.
5. Find the cause of performance problem in SQL and we are done.
6. Capture application memory dump.
7. Generate memory dump report and find suspicious function call in the report.
8. Go back to source code to think why the code is stuck at runtime.
9. If the source code does has inferior algorithm in place that result in time consuming operation, then we are done, otherwise, move to the next step.
10. We need help from other domain expert.
In most situations, we have performance problems from multiple places and from both application and database, so we need to repeat this process again and again until we can’t detect any significant slow web page anymore. Also, not every single performance problem is fixable or improvable. When the performance problem is improved to the point that can’t go further, then an alternative design to improve user experience should be considered. For example, providing a waiting box or progress bar to tell user the page is loading, though the visual cue can’t make page load faster, but will let user has better impression that system is not stuck in anywhere. This article only barely scratches the surface of performance problem troubleshooting for ASP.NET based enterprise web application. There are more things to be explored by software developer.
Using the Code
The code is developed in Visual Studio 2010. You need to first run the attached Database.sql to create database PerformanceDemo and table inside of it. And then, update connection string in configuration file to reference to your local database.